

【SEOに影響?】構造化データのメリット3つと実装方法を解説
-
UnionMedia編集部
この記事は最終更新日から1年以上が経過しています。
【PR】本ページはプロモーションが含まれています

「構造化データって何?」
「Webページを構造化することでどんなメリットがある?」
構造化データを実装することでメリットがある、ということを耳にしたものの、具体的にどんなメリットがあるのか、何をすればいいのか、といったことがわからない方もいらっしゃるかもしれません。
そこでこの記事では、「そもそも構造化データとは何なのか」についてや、実装するメリット、具体的な実装手順などについて詳しく解説していきます。
関連記事:『SEO対策に効果的なHTMLタグ7つを紹介!書き方も合わせて紹介』
Contents
構造化データとは

構造化データとは、検索エンジンに伝わりやすい形式のデータのことです。
人間ならば、文字や文章を読めばその意味を理解することができます。
しかし、検索エンジンにはそれができず、文字や文章はあくまで「テキストデータ」として解釈することしかできません。
このような背景から、検索エンジンが理解しやすい形である「構造化データ」というものが生まれました。
例えば、以下のようなテキストがあったとします。
■名前:田中一郎
人間が読めば、「田中一郎という名前の人なのだろう」と推測できますが、検索エンジンにとってはこれだけでは情報として不十分なのです。
そこで、後述する「構造化データ マークアップ支援ツール」などを使ってデータを変換することで、以下のようなメタデータ(データの解釈を支援するデータ)が付与されます。
<script type=”application/ld+json”>
{
“@context”: “http://schema.org”,
“@type”: “Person”,
“name”: “■名前:田中一郎”
}
</script>
その結果、検索エンジンがテキストの意味を理解しやすくなり、ページの内容を具体的に伝えられるようになります。
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『構造化データとは?非エンジニアでもよく分かる!初心者向け徹底解説!』
関連記事:『【初心者向け】SEOの専門用語34選!マーケティングの基本を解説』
セマンティックWebとは

構造化データを理解する上で、「セマンティックWeb」という概念は無視できません。
セマンティックWebとは、W3C(World Wide Web Consortium)の「ティム・バーナーズリー」という人が提唱した、「ワールド・ワイド・ウェブ」の利便性向上を図ったプロジェクトです。
※W3C:Webで使われる技術の標準化を進める非営利団体
検索エンジンは、テキストを読み込むこと自体はできるものの、その意味を正しく理解することが困難だとされているため、テキスト(情報)に意味を持たせる必要性が出てきました。
それが、前述の「メタデータ」です。
テキストを「ただの記号」として認識・蓄積している検索エンジンに対し、わかりやすく整形したデータにすることでテキストの意味を伝わりやすくし、それを蓄積させていく、というのがセマンティックWebの考え方となります。
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『構造化データとは?非エンジニアでもよく分かる!初心者向け徹底解説!』
参考:『W3C 【World Wide Web Consortium】 ワールドワイドウェブコンソーシアム』
構造化データとSEOの関係は?

構造化データの実装は、SEOに直接的な影響は与えません。
しかし、構造化データを用いていることで、検索エンジンはコンテンツを把握しやすくなり、インデックス化の促進やリッチリザルトの表示の増加などによりクリック率が高まることが期待できます。
そのため、構造化データの実装は間接的にSEOにプラスに働くと言えるでしょう。
しかし、「ユーザーのニーズを満していない」「他サイトのコピーのような内容」など、元々のコンテンツの質が低ければ、構造化データを実装しても、SEO効果に繋げることは難しいです。
構造化データの実装は、数あるSEO施策の一つに過ぎず、重要なのは「ユーザーファーストなコンテンツを作成できているかどうか」となります。
実際にGoogleは、検索結果上位に掲載される仕組みとして以下のように述べています。
Googleの自動ランキングシステムは、検索エンジンでのランキングを上げることではなく、ユーザーにメリットをもたらすことを主な目的として作成された、有用で信頼できる情報を検索結果の上位に掲載できるように設計されています。
参考:『構造化データとは?マークアップの方法とSEOへの影響』
参考:『有用で信頼性の高い、ユーザー第一のコンテンツの作成 | Google検索セントラル』
参考:『Googleが掲げる10の事実|Google』
参考:『SEOにおける構造化データのメリットとデメリットとは?』
関連記事:『SEOはガイドラインに沿って運用!Googleの5つの公式見解』
構造化データのメリット

構造化データを利用する主なメリットは、以下の3つです。
- 検索エンジンがWebページの内容を理解しやすくなる
- 検索結果画面にリッチリザルトが表示されやすくなる
- 検索結果画面にナレッジパネルが表示されやすくなる
検索エンジンがWebページの内容を理解しやすくなる
構造化データの実装によって、検索エンジンがWebページの内容を一層深く理解できるようになり、掲載されている情報を正確に把握しやすくなります。
例えば、先ほど「■名前:田中一郎」というテキストを例に挙げましたが、名前以外に、年齢や職業などについても、構造化データで記述することによってさらに正確に検索エンジンへ伝えることが可能です。
また、構造化データを用いてWebページの内容を正しく分類することによって、検索エンジンによるインデックスが効率的に行われやすくなるというメリットもあります。
その結果、新規追加したコンテンツや、リライトしたコンテンツが迅速に検索結果へ反映されやすくなるでしょう。
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『構造化データとは?SEOへの影響とメリット、実装方法を徹底解説』
参考:『構造化データとは?メリット・デメリットやマークアップ方法を解説』
検索結果画面にリッチリザルトが表示されやすくなる
二つ目のメリットとしては、検索結果画面にリッチリザルトが表示されやすくなる、という点です。
リッチリザルトとは、通常よりも目立つ形で検索結果に表示される機能のことを指します。
例えば、以下のような形です。
■料理におけるレシピの例
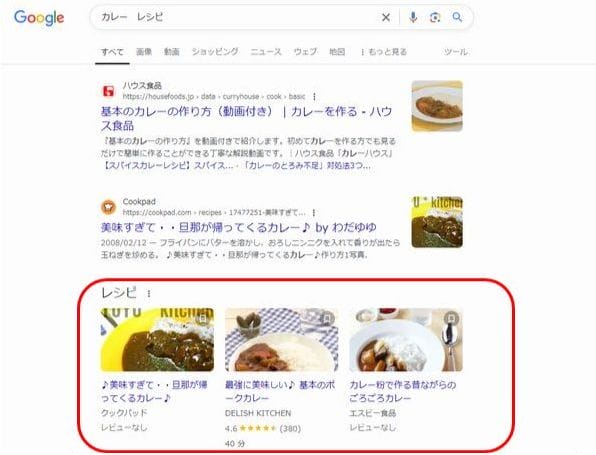
上記画像の通り、こちらは「カレー レシピ」というキーワードで検索した例ですが、上位に2つのサイトが表示された後、1位や2位よりも目立つ形で赤枠部分が表示されています。
これがリッチリザルトです。
上記のレシピには、タイトルとともに、調理時間やレシピの評価なども表示されています。
このように、リッチリザルトは、普通に表示される検索結果よりも情報量が多いため、ユーザーからクリックされやすくなったり、競合する他サイトとの差別化を図ったりすることが可能となります。
実際にGoogleに掲載されている事例でも、検索結果でリッチリザルトが表示されないページに比べて、リッチリザルトが表示されるページの方がクリック率が82%高いという結果が出ています。
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『構造化データとは?SEOへの影響とメリット、実装方法を徹底解説』
参考:『構造化データとは?メリット・デメリットやマークアップ方法を解説』
参考:『Google検索での構造化データのマークアップの仕組み概要|Google検索セントラル』
関連記事:『【基礎】リッチリザルトとは?3つの効果と代表的な機能を紹介!』
検索結果画面にナレッジパネルが表示されやすくなる
構造化データを使用することで、検索結果画面にナレッジパネルが表示されやすくなります。
ナレッジパネルとは、Googleで検索した際に、検索結果の右側に表示される情報ボックスのことです。
ナレッジパネルは、ナレッジグラフに存在する対象(人、場所、組織、物事など)を検索したときに Google に表示される情報ボックスです。
あるトピックに関する概要を簡単に確認できるようにするためのものであり、ウェブ上で利用可能なコンテンツについて Google が把握している内容に基づいています。
例えば、「Google」と検索した場合、以下のような検索結果画面が表示されます。
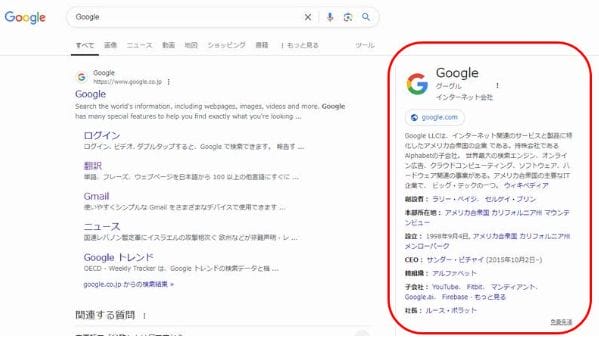 このように、右側にある赤枠で囲った部分に、検索対象についての概要が表示されます。
このように、右側にある赤枠で囲った部分に、検索対象についての概要が表示されます。
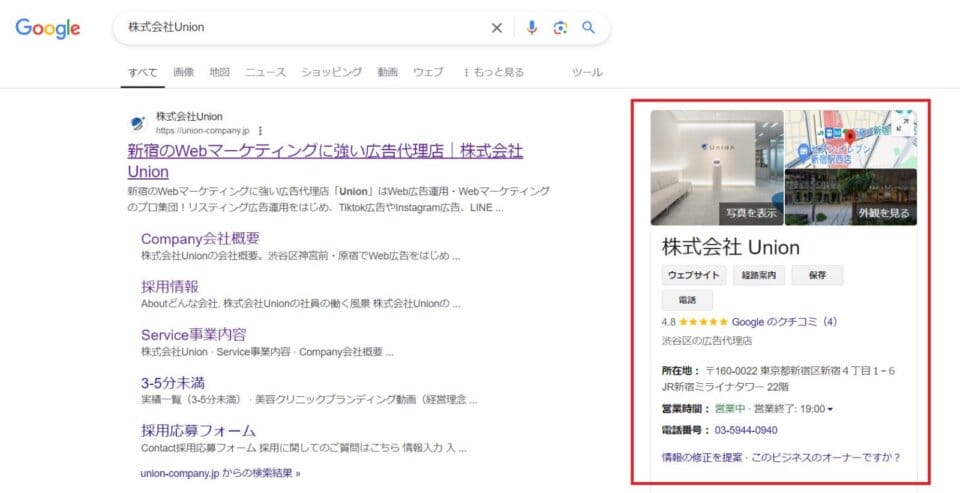
ナレッジパネルには、住所や電話番号、自社サイトのURLやマップなどを表示することができるため、Webサイトへのアクセスや、お問合せの増加が期待できます。
ただし、ナレッジパネルに表示される情報は、検索エンジンのクローラーが収集した情報がもとになっているため、必ずしも自社が意図している情報を表示できるというわけではないので、その点のみ注意が必要です。
参考:『構造化データとは|メリットやSEO効果を高めるマークアップ方法を解説』
参考:『ナレッジパネルとは?表示方法の仕組みと表示されやすくするための3つの方法』
関連記事:『【初心者向け】SERPとは?代表的な9種類や分析方法を紹介!』
構造化データのデメリット

構造化データの実装には、メリットだけでなくデメリットも存在します。
例えば、以下のようなものです。
- 構造化データを利用するための専門知識が必要になる
- 実装・テストの手間がかかる
構造化データを利用するための専門知識が必要になる
構造化データを実装するには、専門的な知識が必要となる点はデメリットと言えるでしょう。
メタデータを定義するのに必要となる属性・属性値は数多く存在しますし、そのうえ、属性や属性値は増加していきます。
したがって、構造化データに関する基本的な学習はもちろん、追加仕様に関する勉強も欠かせません。
まず、Googleは「JSON-LD形式」を推奨しています。
一般的に、Googleは実装と管理が最も容易な形式(ほとんどの場合はJSON-LD)を推奨します。
マークアップが有効であり、機能のドキュメントに基づいて適切に実装されている限り、3つの形式はいずれもGoogleにとって適した形式です。
しかしその他にも、「microdata」や「RDFa」といった形式も存在します。
各形式によって記述の仕方が変わってくるため、構造化データに関する専門的な知識がないと対応するのが難しいでしょう。
構造化データに対応できる人材が自社にいない場合は、Web制作に強い会社やフリーランスといった外部のリソースを利用するのも一つの方法です。
参考:『Google 検索での構造化データのマークアップの仕組み概要 | Google検索セントラル』
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『SEO対策における構造化データとは?メリット・デメリットやJSON -LDを用いた使用例を解説』
参考:『構造化データとは|メリットやSEO効果を高めるマークアップ方法を解説』
参考:『構造化データとは?メリット・デメリットやマークアップ方法を解説』
実装・テストの手間がかかる
構造化データを実装し、それが有効化されるまでには、手間や時間がかかってしまうというのもデメリットの一つでしょう。
まず、構造化データを正しく実装するためには一定の作業時間が必要になりますし、実装内容が意図したものになっているかどうかチェックする時間も設けなければいけません。
Webサイトのページ数が多ければ多いほど、それだけ時間と手間がかかってしまいます。
そのため、大量のページがあるWebサイトで構造化データを実装する場合、優先順位をつけるなどの工夫が必要となるでしょう。
また、構造化データは実装して終わりではありません。
テストを行い、正しく記述できているかを確かめる必要があります。
なぜならば、構造化データに1文字でも記述ミスがあると、正しく動作しなくなってしまうからです。
構造化データの実装にはメリットも多いものの、このようなデメリットがあることも事前にしっかり把握しておくことが重要です。
参考:『SEO対策における構造化データとは?メリット・デメリットやJSON -LDを用いた使用例を解説』
参考:『構造化データとは|メリットやSEO効果を高めるマークアップ方法を解説』
構造化データの構成要素

構造化データについて理解を深めるには、「ボキャブラリー」と「シンタックス」の2つの要素について知っておくべきです。
この項目では、ボキャブラリーとシンタックスがどういったものなのかについて解説していきます。
ボキャブラリー
ボキャブラリーとは、Webページ内にある情報を定義するための規格です。
辞書のようなものとも言えるでしょう。
例えば、名前ならば「name」、住所ならば「address」、商品ならば「product」、といったように、テキストの意味が検索エンジンに伝わりやすくなるように、どのような意味があるテキストなのかを定義づけるという役割があります。
ボキャブラリーとして代表的なのは「Schema.org」です。
Schema.orgは、「Google」「Yahoo!」「Microsoft」の3社によって策定されたボキャブラリーで、この規格に沿って正しく構造化することで、検索エンジンに情報が正しく伝わりやすくなります。
Googleでも、主にSchema.orgが使用されていることから、構造化データのマークアップの際はこちらの規格を用いるとよいでしょう。
参考:『構造化データとは?SEOへの影響とメリット、実装方法を徹底解説』
参考:『SEO対策における構造化データとは?メリット・デメリットやJSON -LDを用いた使用例を解説』
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『構造化データによるマークアップのメリットや書き方、検証方法まで解説』
参考:『schema.org のご紹介: より便利なインターネットのための検索エンジンの取り組み | Google検索セントラル』
シンタックス
シンタックスとは、構造化データを記述する際の仕様・ルールのことです。
構造化データは、決められたフォーマットで記述しなければなりません。
あらかじめ定められたフォーマットに従う形で構造化データを実装すれば、検索エンジンへ正しく情報を伝えられるようになります。
なお、主なシンタックスの種類は以下の3つです。
- JSON-LD
- Microdata
- RDFa
各形式の詳細について、Google検索セントラルでは以下のように説明されています。
JSON-LD*(推奨) HTMLページの<head>および<body>要素の<script>タグ内に埋め込まれるJavaScript表記。このマークアップにはユーザーに表示するテキストをそのまま挿入しないため、ネストされたデータアイテム(EventのMusicVenueのPostalAddressのCountryなど)を簡単に表現できます。また、Googleは、コンテンツマネジメントシステムのJavaScriptコードや埋め込みウィジェットなどでページのコンテンツに動的に挿入されるJSON-LDデータも読み取ることができます。 microdata HTMLコンテンツ内に構造化データをネストするために使用される、オープンコミュニティのHTML仕様。RDFaと同様に、HTML タグ属性を使用して、構造化データとして公開するプロパティに名前を付けます。通常は <body>要素で使用しますが、<head>要素でも使用できます。 RDFa 検索エンジンに伝えたいユーザー表示コンテンツに対応する HTMLタグ属性を追加することによってリンクデータをサポートする HTML5の拡張機能。RDFaは一般に、HTMLページの<head> と<body>の両方で使用されます。
前述の通り、Googleは「JSON-LD形式」を推奨していますので、特別な理由がない限りは「JSON-LD形式」での記述がおすすめです。
参考:『構造化データとは?SEOへの影響とメリット、実装方法を徹底解説』
参考:『SEO対策における構造化データとは?メリット・デメリットやJSON -LDを用いた使用例を解説』
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『Google検索での構造化データのマークアップの仕組み概要 | Google検索セントラル』
構造化データのマークアップ方法

構造化データのマークアップ方法としては、主に「HTMLで直接記述する」「Googleが提供する構造化データマークアップ支援ツールを活用する」の2パターンとなります。
なお以下の例は、<head>タグと<body>タグのどちらに記述しても問題ありませんが、必ず<script>タグで囲む必要があります。
HTMLで記述する
まず一つ目の方法は、HTMLを使って直接マークアップするという方法です。
HTMLを編集できる画面やファイルを開き、「Schema.org」の規定に則った形でボキャブラリーを記述していきます。
シンタックスは、できればGoogleが推奨する「JSON-LD形式」がよいでしょう。
以下に、企業情報の例としてHTMLで構造化データをマークアップする際の具体例を紹介します。
<script type=”application/ld+json”>
{
“@context”: “https://schema.org/”,
“@type”: “corporation”,
“name”: “Example株式会社”,
“url”: “https://example.co.jp “,
“logo”: “ロゴ画像を格納したURL”,
“telephone”: “03-0000-0000”,
“address”: {
“@type”: “PostalAddress”,
“streetAddress”: “■■1-2-3-999”,
“addressLocality”: “新宿区”,
“addressRegion”: “東京都”,
“postalCode”: “000-0000”,
“addressCountry”: “JP”
}
}
</script>
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『SEO対策における構造化データとは?メリット・デメリットやJSON -LDを用いた使用例を解説』
参考:『構造化データとは|メリットやSEO効果を高めるマークアップ方法を解説』
構造化データのマークアップ支援ツールを活用する
構造化できるデータがある程度限られてしまうものの、Googleが提供する「構造化データマークアップ支援ツール」もおすすめです。
構造化データの実装に関して専門知識を持たなくとも、こちらのツールを使うことで、簡単に構造化のためのマークアップを行うことが可能となります。
それでは、以下の手順で解説していきます。
- 「構造化データアークアップツール」を開きデータタイプを選択
- 該当するURLを入力
- 「タグ付けを開始」をクリック
- 構造化データを生成
- 生成された構造化データをWebサイトへ反映
➀「構造化データマークアップ支援ツール」を開きデータタイプを選択

はじめに、「構造化データマークアップ支援ツール」の画面を開き、データタイプを選択します。
例えば、記事ページをマークアップしたい場合は、右下にある「記事」をチェックします。
➁該当するURLを入力
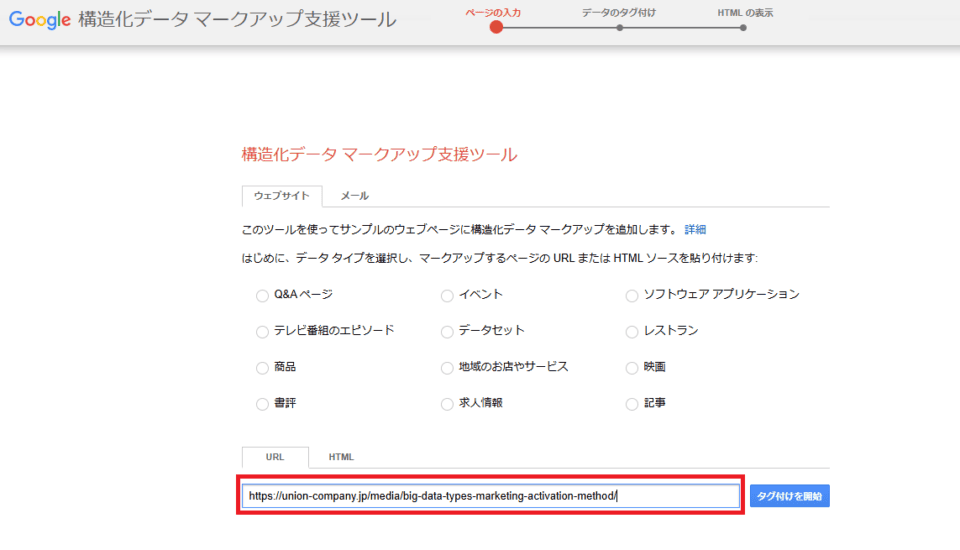 それから、「URL」という欄に、該当のURLを入力してください。
それから、「URL」という欄に、該当のURLを入力してください。
なお、まだ公開していないローカルファイルをマークアップする際は、タブを「HTML」に切替え、入力欄にHTMLソースを貼り付けます。
➂「タグ付けを開始」をクリック
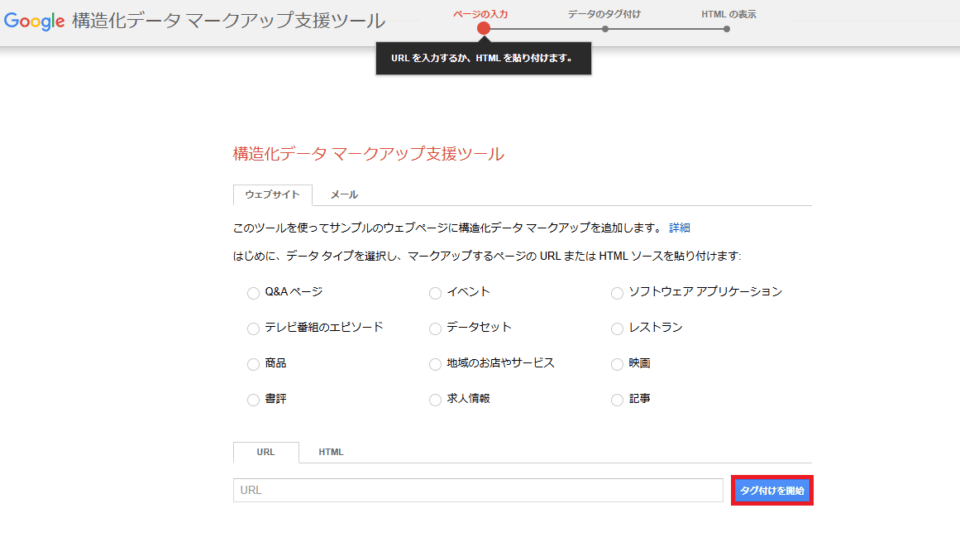 入力が完了したら、「タグ付けを開始」というボタンを押してください。
入力が完了したら、「タグ付けを開始」というボタンを押してください。
➃構造化データを生成
その後、読み込んだページのプレビューが表示されるので、構造化データの設定をしたい項目を選択して適切なデータタイプを選択することで、構造化データとしてマークアップするためのソースが生成されます。
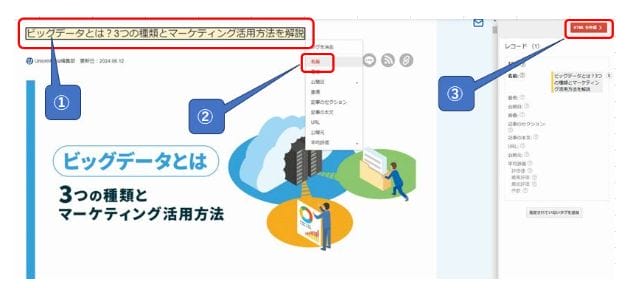 上記の例では、まず記事タイトル(①)をハイライトし、タグ付けとして「名前(②)」をクリックしています。
上記の例では、まず記事タイトル(①)をハイライトし、タグ付けとして「名前(②)」をクリックしています。
そうすると、右上にある「HTMLを作成(③)」というボタンが有効化されるので、それをクリックすると、構造化データとしてマークアップされたソースが生成されます。
⑤生成された構造化データをWebサイトへ反映
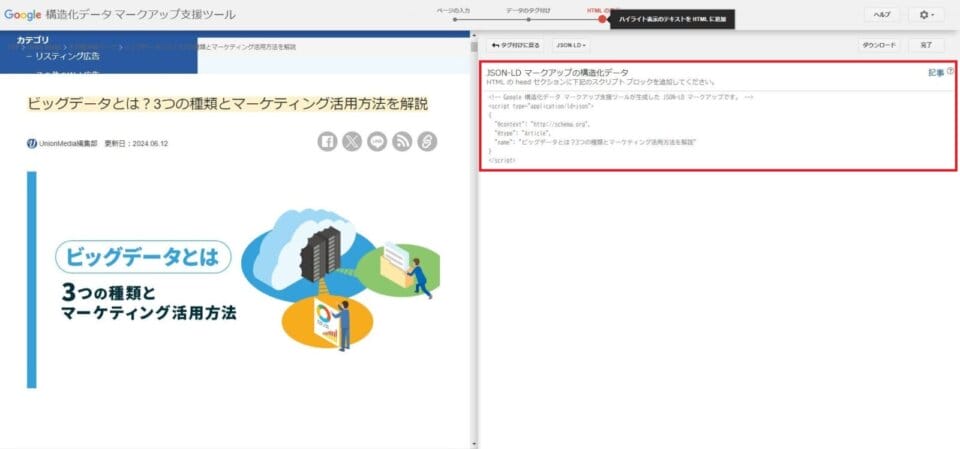
生成された構造化データを、Webサイトに反映させて、実装します。
これで構造化データのマークアップが完了です。
参考:『構造化データ マークアップ支援ツール | Google Search Consoleヘルプ』
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『構造化データとは|メリットやSEO効果を高めるマークアップ方法を解説』
参考:『構造化データとは?SEOへの影響とメリット、実装方法を徹底解説』
構造化データを確認する方法

構造化データが正しく実装できたか確認する方法としては、「Googleが提供するリッチリザルトテスト」を利用するのがよいでしょう。
手順としては、まずGoogleの「リッチリザルトテスト」ページを開きます。
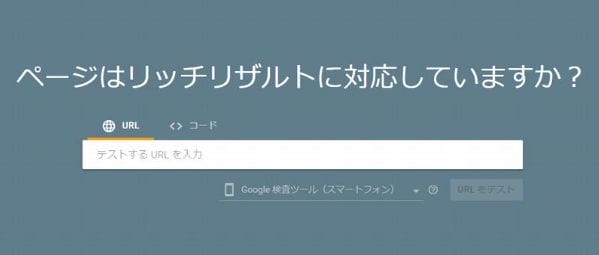
「テストするURLを入力」の欄に、テストしたいURLを入力してから、右下にある「URLをテスト」というボタンをクリックします。
すると、対象のURL内で構造化されているページが表示されますので、各ページを確認し、必要に応じて修正を行ってください。
参考:『リッチリザルト テスト | Google Search Console ヘルプ』
参考:『【初心者必見】構造化データとは?実装方法やメリット、検証方法について解説』
参考:『構造化データとは?SEOへの影響とメリット、実装方法を徹底解説』
構造化データを実装したことによる成功例

構造化データを実装したことによって成功した実際の例として、大手ネットショッピングサイト「楽天」の事例が紹介されています。
楽天では、構造化データを実装したことで「ユーザーのページ滞在時間」を伸ばすことに成功しました。
「構造化データがあるページ」と「構造化データがないページ」を比較すると、構造化データがあるページの方が1.5倍もユーザーの滞在時間が伸びたのです。
その他にも、英語圏の作品に対する映画レビューサイトである「Rotten Tomatoes」にて、10万ものページに構造化データを追加したところ、クリック率が25%上昇したというケースもあります。
参考:『Google検索での構造化データのマークアップの仕組み概要|Google検索セントラル』
まとめ
以上、構造化データを実装するメリットやデメリット、SEOへの影響、具体的な実装方法などについて解説してきました。
構造化データに対応するにはそれなりの専門知識が必要となるものの、実装しておいて損はないため、SEOによるWeb集客を促進したいという場合には極力対応するようにしておきましょう。
株式会社Unionでは、Webサイト制作をはじめとするデジタルマーケティング全般のご相談を承っております。
Google及びYahooの広告運用パートナーとして、豊富な知識と経験を活かし、課題解決へとナビゲートいたします。
自社メディアの運用実績も活かし、データ分析に基づく具体的な提案をいたしますので、お気軽にお問い合わせください。
監修者
2012年創業、新宿のWebマーケティングに強い広告代理店「株式会社Union」が運営。Webマーケティングの知見を深め、成果に繋がる有用な記事を更新しています。「必要な情報を必要な人へ」をスローガンに、Web広告運用や動画制作など各種Webマーケティングのご相談を受付中。